aws
Cloudcraft Alternative Hava.io
If you are looking for a viable Cloudcraft alternative, drag and drop free, that generates AWS, GCP, Azure and hybrid diagrams, with security...

If you are responsible for cloud infrastructure there is every chance the importance of containing or reducing cloud costs this year will become a focus of your organisation.
You need to get one step ahead.
With gloomy economic storm clouds on the horizon, some organisations will be looking towards cloud estate rationalization to reduce the size of their cloud provider bill. Whether your business is impacted negatively or continues to thrive as many do during tougher times, reducing unnecessary operational costs just makes sound business sense.
When you are armed with an accurate auto generated diagram of your cloud infrastructure, you know, the stuff that's actually running right now, you have visual prompts that will enable you to answer the following questions:
When you can see all the resources configured and running in your cloud environment in diagram form, you can start to more easily assess whether things like multiple compute instances are really necessary. Are autoscaling minimum instance numbers set at the right level, or do you have too many instances deployed but sitting idle due to traffic levels not meeting initial expectations.
You can systematically review all the resources discovered when your live diagram was auto generated to see if there is an opportunity for consolidation.
When you produce a network infrastructure diagram via automation, it will discover everything running in your cloud configuration. All the virtual networks, subnets, resources, containers etc etc which can throw up some unexpected surprises. Surprises that you wouldn't go looking for in your console.
This could be significant, like a large AWS RDS instance that was copied for analysis once and never deleted, or maybe an entire dev or staging environment belonging to long gone dev teams or external consultants.
A real world example is one of our clients discovered a running database that was adding four figures a month to their AWS bill and had been for at least three years. What have you got running that is buried deep in your cloud bill?
Once you can see all your running resources, you can better assess whether they are the appropriate size or instance type. If a compute instance has been deployed with massive amounts of RAM or CPU and the usage stats show that you only ever use 10% of that compute power or memory, then you have the opportunity to move to a smaller and usually significantly cheaper instance type.
Depending on the workloads you are running, there may be the opportunity to use spot instances or reserved instances to drive down costs. If for instance you have batch processing micro services that can afford to wait for cheaper spot instance compute power to become available, then deploying spot instances can result in significant savings.
If your infrastructure is settled in for the long run, then committing to a 12 month reserved instance can result in massive savings over pay as you go pricing.
This strategy calls for well considered design but can pay off in the long run.
When you design cloud infrastructure, you decide where your databases live, where your backup locations are located which is hopefully in close proximity to the bulk of your users.
You might also be using other services to ingest log traffic, process data streams or monitor resources and typically these services incur data transfer costs.
Seeing your running resources and the regions they are running in can be a good prompt to help you check that the services that incur data transfer costs are close together, or that source and target data locations are in the same subnet which for some operations might mitigate network charges all together.
In a traditional on premise network, you are responsible for EVERYTHING! Sourcing and commissioning hardware, network routers, server software, operating systems, patching, even fixing that noisy fan on the database server.
All of this takes skill, time and the most expensive element, people.
Part of the beauty and attraction of cloud, is that you get to use other people's hardware that they look after. There are other opportunities though. Some services like compute instances or containers give you the option of taking care of everything from the operating system up. This puts the onus and staff requirements on your organisation (including the payroll bill) to keep everything running.
There are also fully managed options, where the cloud provider keeps everything running, patched and up to date without your team needing to get involved like running containers on AWS Fargate. They just get to focus on your applications. Reviewing what you need to manage yourself vs managed services might present some opportunities for cost savings.
When your application experiences massive traffic spikes, you need all the load balanced compute instances you can muster. Black Friday, Cyber Monday, Just because Tuesday, whatever the reason, you need the resources in place to cope with the load.
But you don't need them 24x7x365. Permanently deploying compute instances to handle the peaks could see them sitting around for the majority of the year idle.
Implementing autoscaling with a minimum instance count set at the appropriate value to handle normal day to day traffic with the ability to scale out when traffic spikes will ensure you are not paying for resources that are unused or underutilized. Running 5 EC2 instances at 10% capacity is obviously a lot more expensive than running one at 50% capacity.
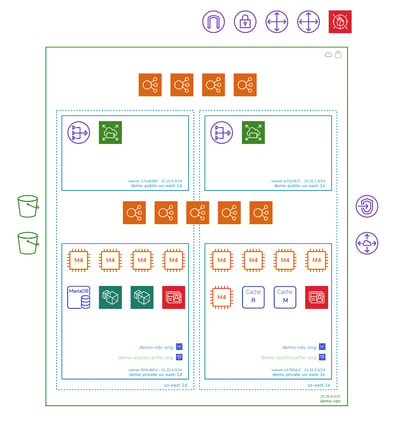
Reviewing visualised VPC infrastructure will show you what instances are attached to your load balancers and from there you can assess whether implementing auto scaling or adjusting the minimum instance count could save you some money.
As the saying goes, you can't manage what you don't measure. Most cloud platforms allow you to report on costs, set budgets and send alerts when cloud spend is approaching budget. Correctly tagging resources and attributing them to departments or projects allows you to see where the money is going.
Going to the effort of setting budgets and breaking down costs can uncover unexpected cost silos. Why is the dev team burning cash like it is going out of fashion? Maybe it's the 12 duplicate test environments that are permanently running, or the staging environments still running from an application that went into production years ago. Who knows, but running a close eye over environment costs may uncover the opportunity to kill off resources that nobody needs.
The auto generate nature of Hava diagrams will surface such things. The diagrams also carry cost estimates at individual resource level, so you can see what is costing the most money in each VPC or virtual network by simply opening up the List View and sorting the report by costs.
Your dev team are superstars, you give them fast high performing resources so they can efficiently do whatever it is that they do. But do they really need all that compute power out of hours or over the weekend?
If you have teams around the globe, then the answer might be yes, however if you have developers located in a single region and dev environments that sit untouched for 16 hours a day or 60+ hours between knock off Friday and start of business Monday then you may have the opportunity to reduce the costs of those dev/test environments by as much as 76% by stopping the resources in those dev environments when they are not in use.
It the same for microservices. If you have batch processes that run once a week, does the supporting infrastructure need to be started 24/7 seven days a week.
Stopping resource instances isn't rocket surgery, but does require careful consideration and some work, but the payoff can be substantial.
While not a day to day cost reduction strategy, having a solid disaster recovery plan can mitigate lost revenue and reputation following an outage.
Do you have everything in place to spin up replacement infrastructure and restore the required data so your application is back online fast and your users can continue their work, or shopping, or enjoying your content.
There are steps you can take to mitigate the impact of disasters. Say for instance an AWS availability zone has an outage. Has your infrastructure design anticipated this unlikely but somewhat inevitable scenario. A quick glance at a Hava infrastructure view will show you all your resources and where they live. You can see at a glance what would disappear during an AZ outage and from there you can assess whether your application would persist and also have access to the databases it needs.
There are a ton of obvious and less obvious steps you can take to drive down cloud costs in 2023. We haven't discussed comparing cloud providers and migrating to more competitive infrastructure, maybe that's a post for another day. What we have discussed are some concrete tactics you can use to drive down cloud costs.
In most examples, having cloud infrastructure diagrams at the VPC or virtual network level facilitates the discovery of such cost saving opportunities or at least creates prompts that allow you to dig a little deeper.
The major advantage you have using Hava over other diagramming methods is the auto generation process. All you do is connect Hava to your cloud account and diagrams are generated based on what is configured and running in your cloud console. The diagrams are generated automatically and detail every resource instance whether you are aware of them or not.
This provides additional opportunities to eliminate resources or entire environments which may well be missed or harder to identify from console settings, or at least not without spending a lot of valuable time mapping things out manually (oh was that another cost saving).
If your AWS, GCP or Azure monthly costs are spiralling out of control or are the target of budget cuts, you can grab a free 14 day trial of Hava's fully featured teams plan and start work on your cost reduction strategy today.

Use the button below to learn more:

If you are looking for a viable Cloudcraft alternative, drag and drop free, that generates AWS, GCP, Azure and hybrid diagrams, with security...
If you are looking for a viable Arcentry alternative, drag and drop free, that generates AWS, GCP, Azure and hybrid diagrams, including security...
If you are looking for a fully automated, hands-free cloud network diagram solution as an alternative to Lucidchart Cloud Insights, we invite you to...