aws
What is Amazon AWS DataSync
AWS DataSync allows you to quickly transfer data from on premise file storage or between AWS services. In this post we take a closer look at the...

Amazon Redshift is a fully managed data warehouse solution from AWS that allows you to store and query large volumes of analytical data. It is fast and scalable providing a 10x performance lift over other data warehouses by using machine learning and parallel processing of queries against columnar storage held on very high performance disk.

The difference between a traditional relational database like Amazon Aurora is that a relational database is designed to store individual transactional data and records, whereas data warehouses are designed to store aggregated data from multiple sources like relational databases and S3 buckets.
Amazon Redshift data warehouses can be provisioned quickly. Redshift automatically provisions the resources required for the database and also automates the administrative functions like replication, backups and fault tolerance.
Redshift concurrency scaling provides the ability to store and retrieve almost unlimited amounts of data in your data warehouse. When enabled, concurrency scaling will automatically scale the number of clusters available to process concurrent read queries. When the concurrent query demand subsides, the additional cluster capacity is automatically removed.
Redshift cluster nodes and subnet groups are visualised on Hava's automatically generated AWS architecture diagrams.

Amazon Redshift Spectrum is an optional service that enables you to query all types of data stored in Amazon S3 buckets. The data in S3 does not need to be loaded into the Redshift data warehouse first to be able to be queried by Redshift if you have spectrum enabled.
Internally, redshift is made up of a leader node and multiple compute nodes that present parallel data access in the same format that queries are constructed. There is a single SQL endpoint located on the leader node and as queries are sent to the SQL endpoint, the leader node instantiates jobs in parallel on the compute nodes to perform the query and return the results to the leader node. The leader node, then aggregates the results from all the compute nodes and returns the result to the user.
You can use Amazon Redshift to create a unified data platform. Traditional data warehouses require you to load your data into them in order to query and access that data. This obviously leads to a massive duplication of data which consumes time and effort as well as increased costs.
Using Redshift Spectrum, you eliminate the need to move data from S3 to your data warehouse, as Spectrum allows you to execute queries against both the data you have stored in Redshift and the data stored in S3 simultaneously. This saves you time and money because you can leave data in S3 where it is.

The cost of Redshift is determined by the options you choose.
The first decision is the cluster node type you choose. Nodes have varying levels of memory, storage capacity and io capabilities and are billed per hour.
The next decision is the pricing model that best suits your needs. These pricing models are:
There is no charge for the transfer of data from Redshift to S3 for the purposes of backup, restore, load and unload as long as they are in the same region.
As mentioned, a Redshift cluster consists of a leader node and multiple compute nodes. The leader node distributes jobs to the compute nodes which each have their own memory, cpu and disk storage.
Compute nodes are divided into slices with each slice being allocated a portion of the cpu, disk space and memory available. These resources are used to process the portion of a job submitted to the node slice. Once the compute process is complete, the node aggregates the results from each slice and sends it back to the leader node.
Once the leader node receives the job results from all the parallel nodes, it aggregates the result and passes it back to the client who initiated the query.
When you instantiate a Redshift Cluster you are provided with an endpoint for connections which is a combination of a URL and a port number. You use this SQL endpoint to connect your application to Redshift.
Any application with an JDBC or ODBC industry standard driver can be used to establish a PostgreSQL connection to Redshift.
Security is the primary concern when building applications or storing data in the cloud. Amazon Redshift integrates AWS Identity and Access Management (IAM) to control access. IAM policies determine who can access and manage Redshift resources.
When you create a Redshift cluster, it is created inside an AWS VPC (Virtual Private Cloud) which isolated the cluster within your own private network which is not by default publicly accessible.
Data in transit is secured via https secure socket layer encryption.
Data at rest in the Redshift database files is secured using AES 246 bit encryption with the encryption key management handled by the AWS key management service (KMS)
Redshift has native integration with multiple AWS services.
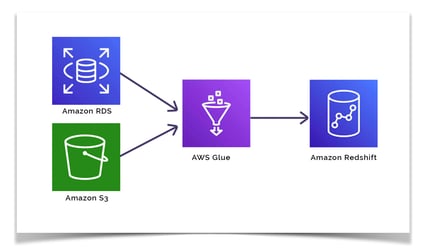
You can for instance use AWS Glue to combine transactional data from an AWS RDS database and also archived data from Amazon S3. Once combined the data can be loaded into your Redshift data warehouse.
Another use case is an event driven data analysis funnel to monitor and analyse on premise customer database transactions.
By connecting Amazon Kinesis Data Firehose and triggering Lambda functions, transaction data can be loaded into an Amazon S3 data lake. Now Redshift can query both the data held within its own data repository and also the data in the S3 data lake using Redshift Spectrum.
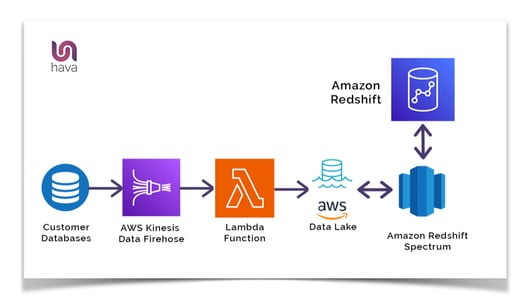
You can then use Amazon QuickSight to visualize the data returned from Amazon Redshift.
Once you have built your Redshift data warehouse you have the ability to execute an unlimited amount of flexible queries to return business intelligence that may have taken hours in just minutes or even seconds.
From the AWS Management Console, navigate to the Redshift home page and take the “Create Cluster” option.
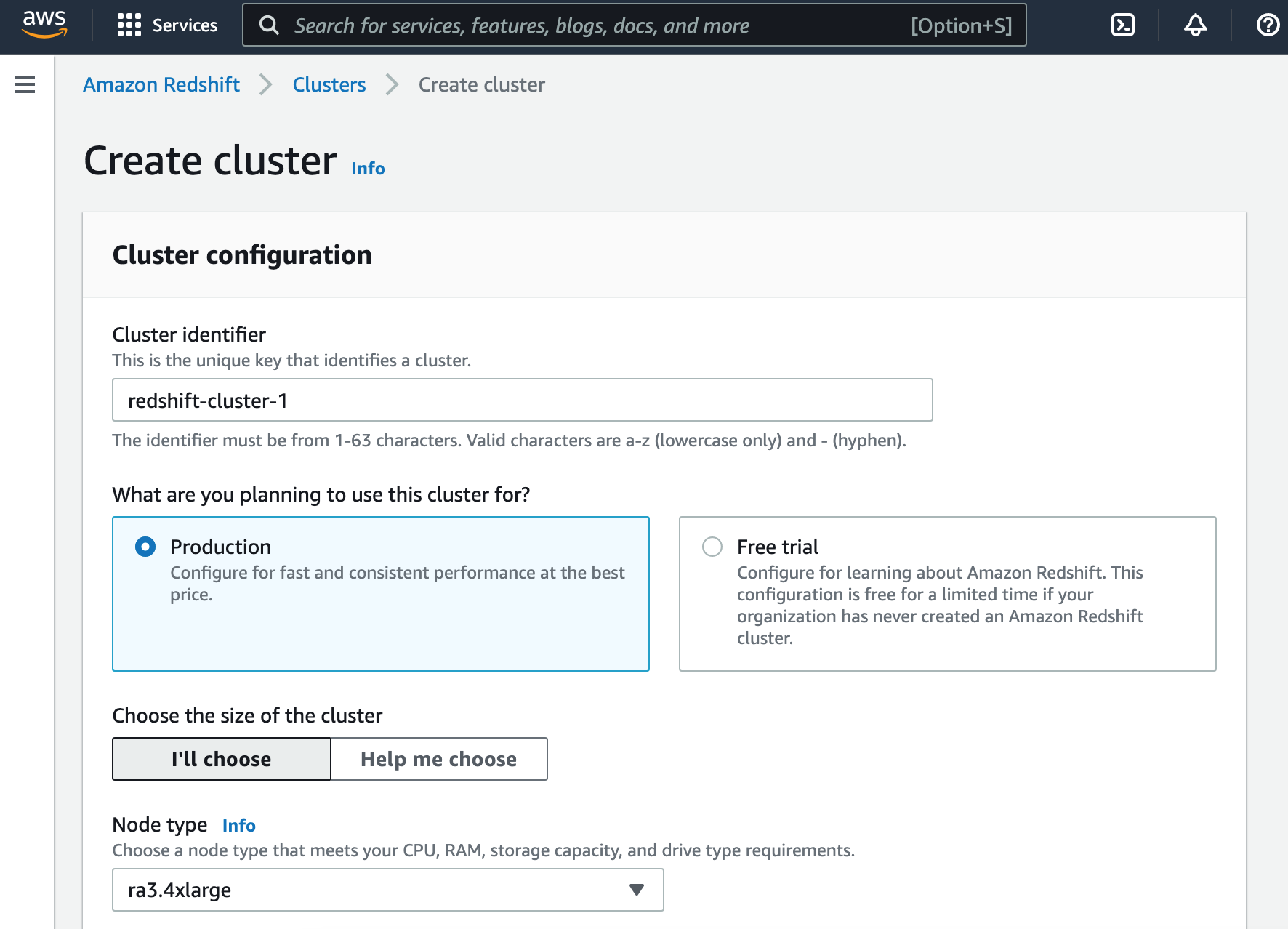
Enter a cluster name in the identifier box.
You can then select either production or free trial which will let you play with Redshift for a limited time without charge.
You then select a node type, which can range from 25 cents to $13 per node per hour depending on the size and compute power of the cluster selected.
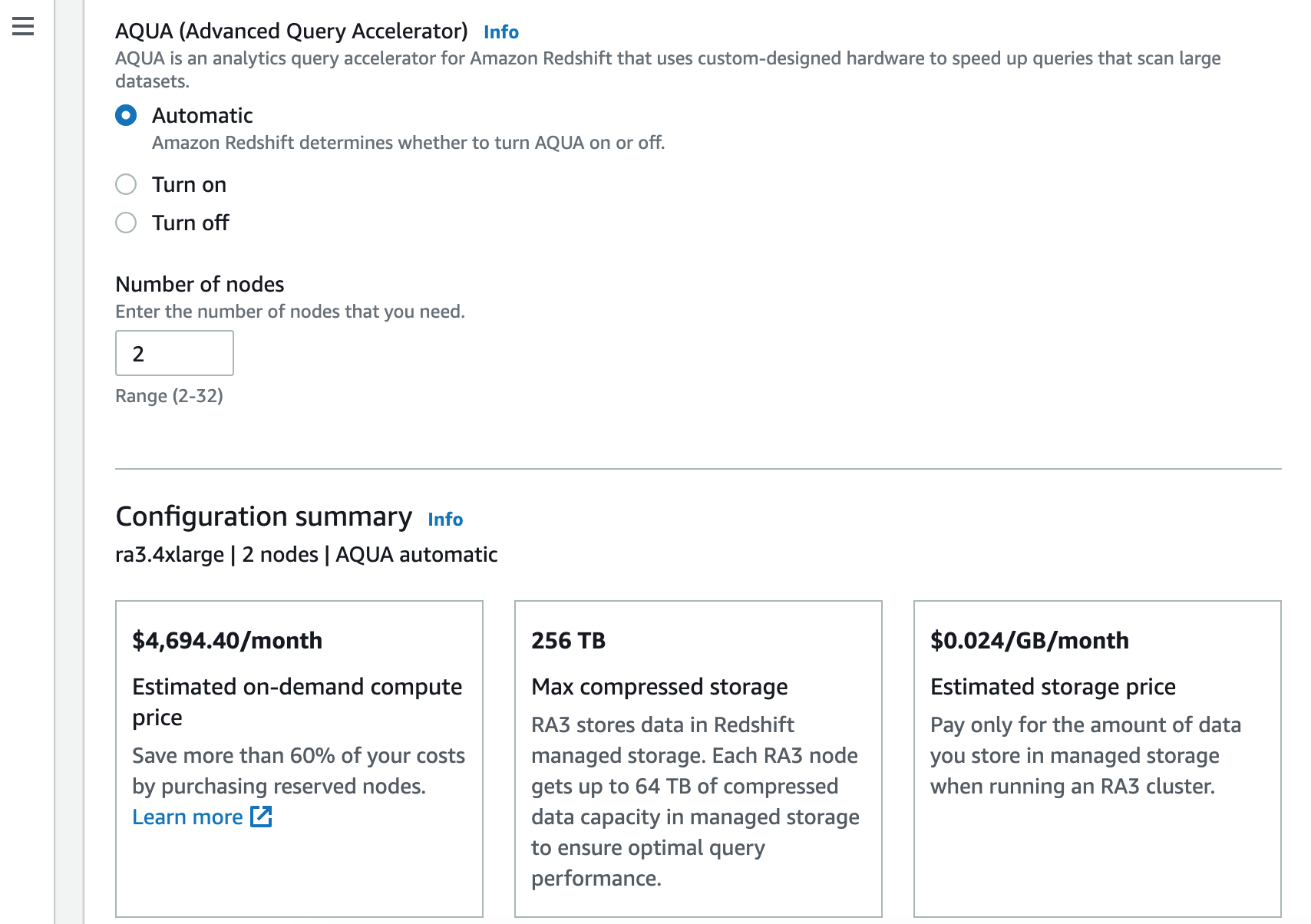
You can then nominate whether to switch AQUA on or off.
The next option is to set the initial number of nodes, bearing in mind that pricing is set on a per node basis, so the higher the number of nodes you set, the more you will be charged as a baseline.
At this point you can see the estimated cost based on your selected configuration options.
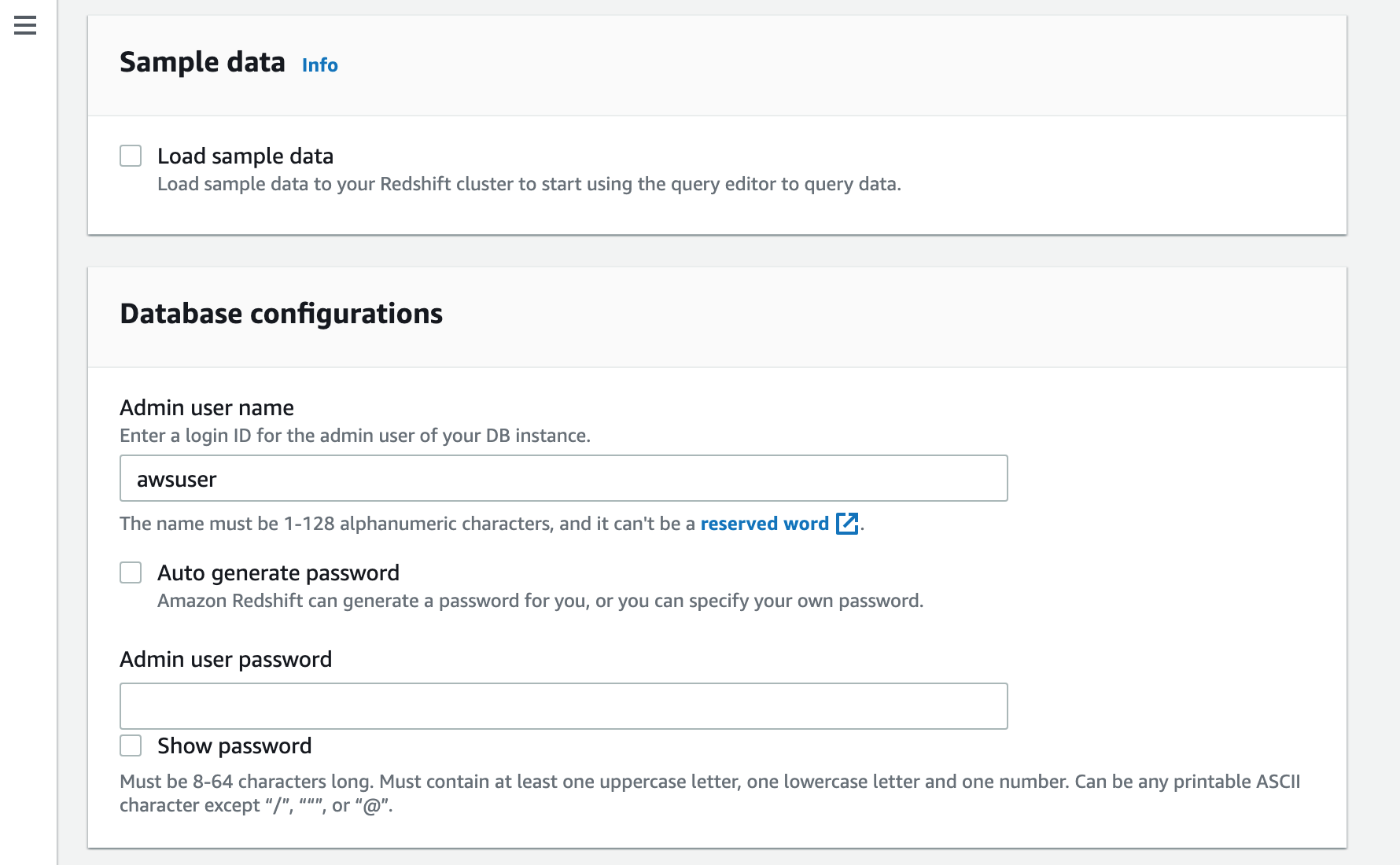
At this point you can opt to load sample data, which is useful if you are just taking a look around to see how things work.
Next enter an admin username and password for the redshift database(s)
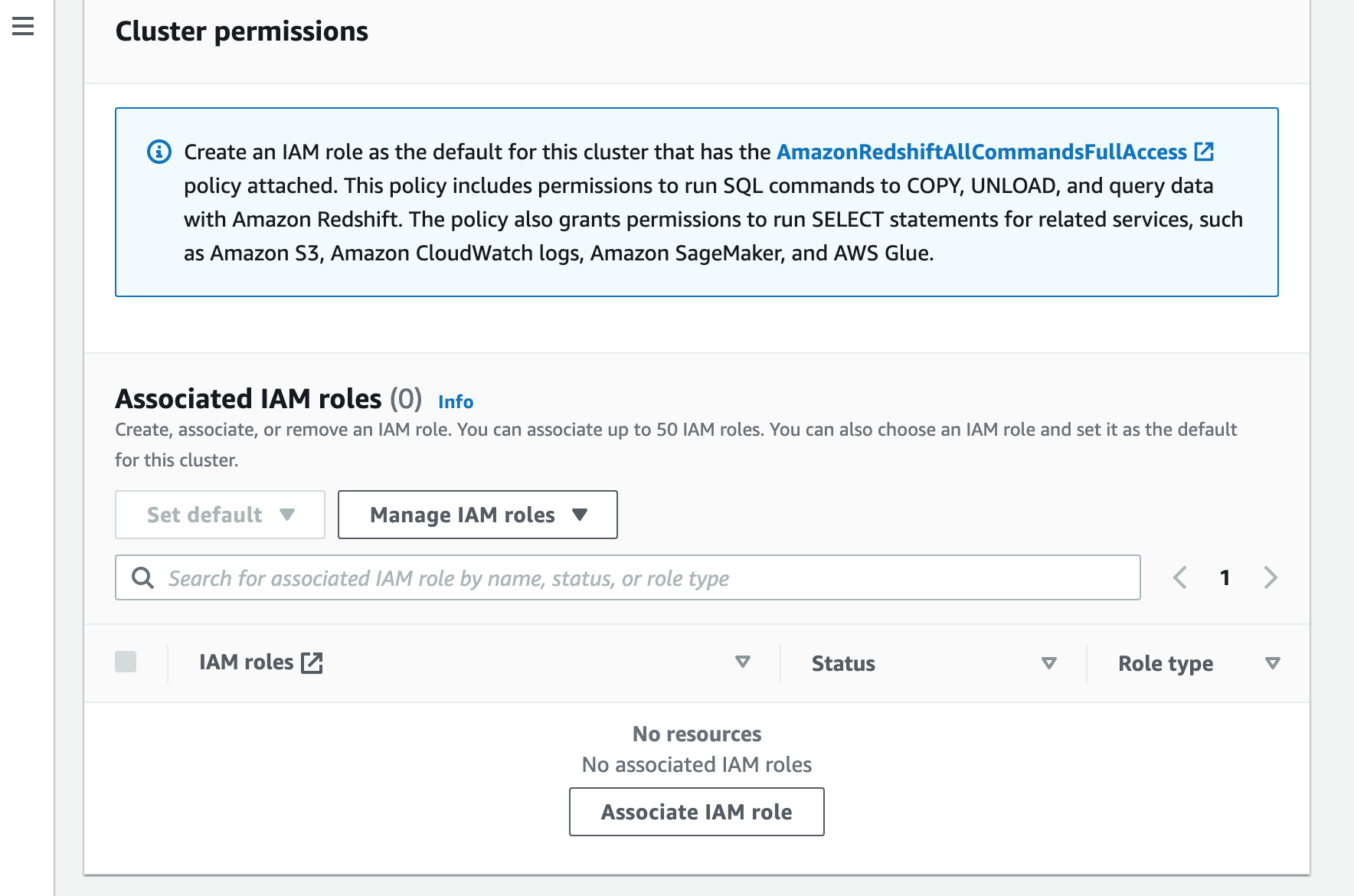
Next you will need to associate an IAM role that has the “AmazonRedshiftAllCommandsFullAccess” policy attached
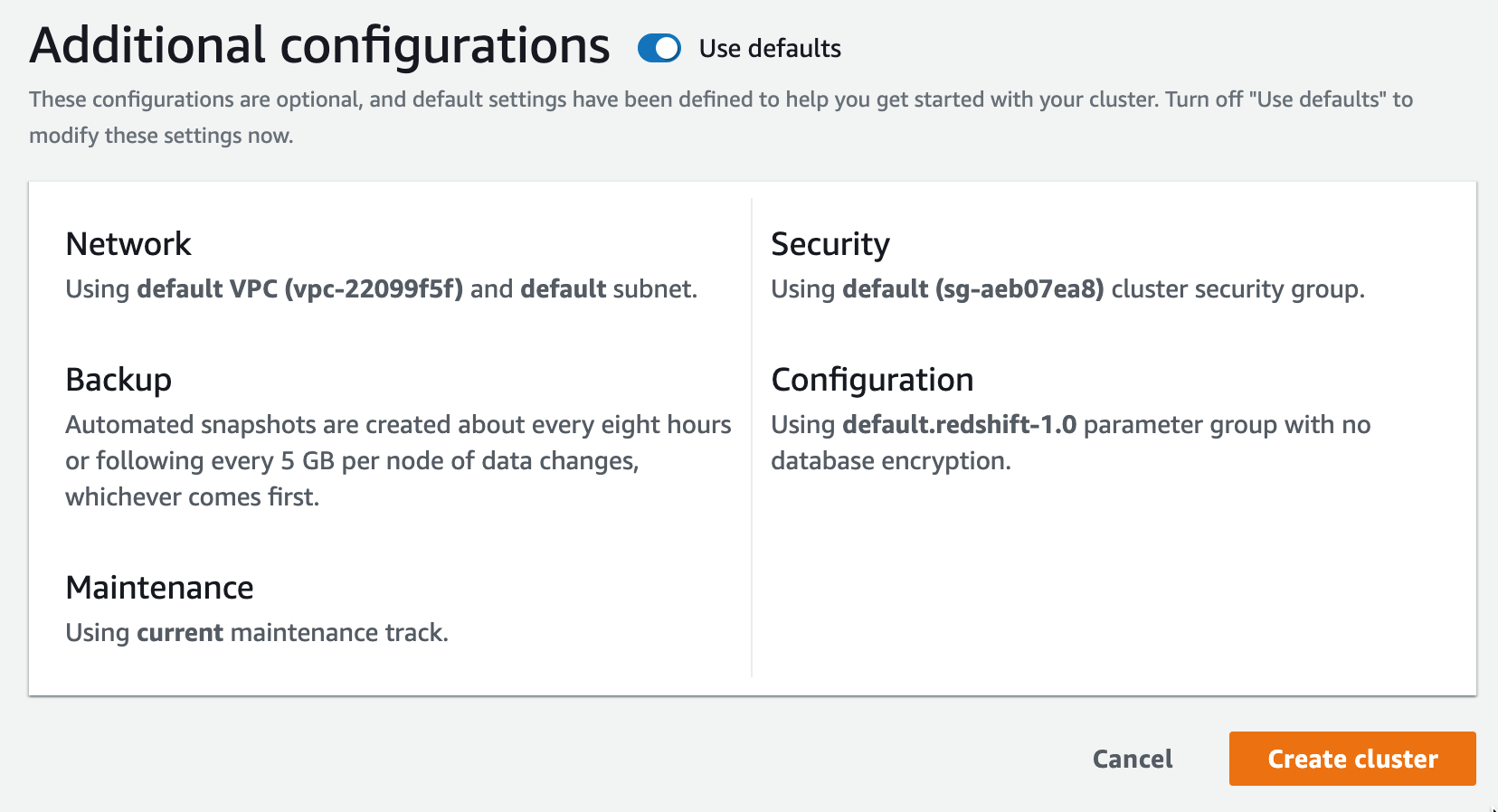
Finally, you can choose to accept or override the default additional configurations that cover the VPC, Security Group, Backup , Maintenance and Encryption settings
You can then select “Create Cluster” and your redshift cluster will build.
Hopefully you have a better understanding of what Amazon Redshift is and what it does. Redshift Clusters are supported by Hava and will be included on auto generated diagrams created when you connect your AWS to either the SaaS or fully self hosted versions of Hava.
If you are not fully automating your cloud diagrams, check out Hava.

AWS DataSync allows you to quickly transfer data from on premise file storage or between AWS services. In this post we take a closer look at the...
What is AWS Glue? We took a look at this serverless data integration service from AWS
Amazon QuickSight is a Business Intelligence service from AWS that allows you to connect a range of data sources and present business data analysis...