aws
What is Amazon AWS Managed Services?
AWS managed services will provision and manage technology stacks for your applications and workloads leaving you free to work on more important...

AWS Glue is a fully managed serverless ETL (extract, transform, load) data integration service you can use to ingest, prepare and combine data from multiple sources. Once in Glue, your data can then be used for analytics purposes, fed into machine learning processes or used with applications you develop.
Glue contains all of the capabilities required to integrate data from different sources so you can get on with the job of analysis and enjoy the results in minutes.
You have the choice of a visual interface or you can use code to perform data integration tasks.
Data is made available to users through the AWS Glue Data Catalog and Data engineers can perform ETL actions to populate the data catalog.
AWS Glue studio enables developers to create and run ETL workflows using a visual interface.
Data scientists and analysts can use AWS Glue Databrew to visually manipulate data to enrich and clean it and normalize data without the need to write code or complex scripts.

Why use AWS Glue?
Using Glue you can speed up your data integration processes. Instead of multiple users or teams using different ETL tools that might lead to slower data preparation times, organisations that leverage AWS glue across their business can get multiple teams working together using scalable ETL workflows to achieve much faster coordinated results.
Data engineers can test ETL code against development endpoints before deploying it as a fully fledged AWS Glue job.
AWS Glue allows you to automate much of the data integration process. You can use Glue to crawl data sources and in the process understand data formats and metadata at which point Glue can suggest a data storage schema. As part of the process, Glue will generate code for the data transformation and loading ETL processes.
Because AWS Glue is serverless, there is no lead time waiting for network architects or engineers to provision the necessary services. Glue maintains a pool of warmed up servers ready to receive and scale in response to your ETL jobs. This means data engineers, analysts and developers can launch jobs and workflows to get the results they need for your business operations without any delays.
In terms of service costs, you only pay for the AWS Glue resources you consume. There are no additional up front startup or shut down costs.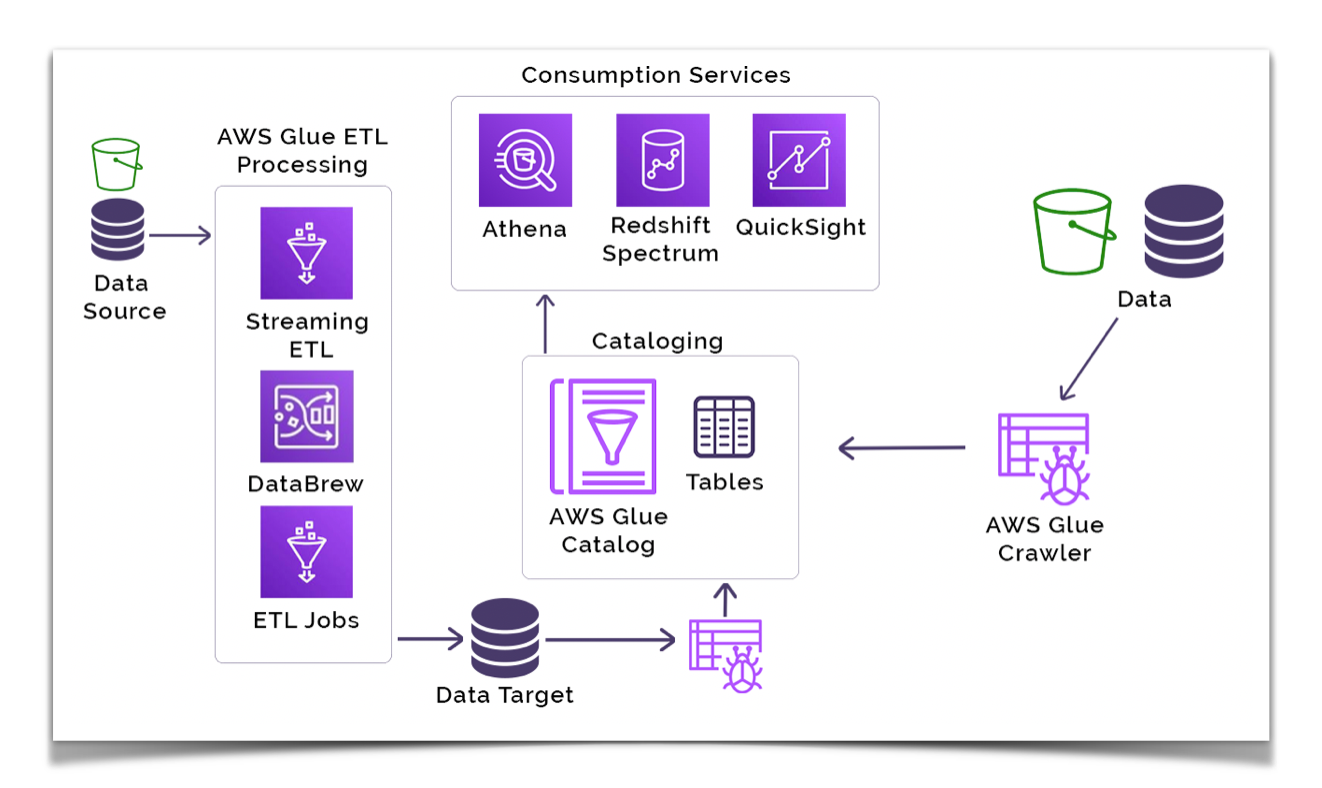
In the above example use case the components that make up the solution are:
Data stores – AWS Glue has the ability to connect to many different types of data sources both on AWS and externally. You can use an AWS Glue crawler to automatically discover and catalog data in the Data Catalog across many different data stores like S3, on premise databases and other cloud providers like GCP.
Data sources and write targets – AWS Glue can read and write to Amazon S3 or databases on AWS or on premises. It can also use a JDBC connection for your external data sources and targets.
AWS Glue natively supports data stored in Amazon Aurora, RDS for MySQL, RDS for Oracle, RDS for PostgreSQL, RDS for SQL Server, Amazon Redshift, DynamoDB and Amazon S3, as well as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in your VPC running on Amazon EC2.
AWS Glue also supports data streams from Amazon MSK, Kinesis Data Streams, and Apache Kafka.
You can also write custom Python or Scala code and import Jar files and custom libraries into your AWS Glue ETL jobs to access data sources not natively supported by Glue.
Glue Data Catalog – As a persistent metadata store, you can use this managed service that is similar to Apache Hive to store, annotate, and share metadata in the AWS Cloud.
The AWS Glue Data Catalog holds all of the information about your tables and table schemas like the physical location of where the data is stored and table properties such as file type, compression type, record size, record count, and more.
If you are currently building solutions in AWS, Azure, GCP or Kubernetes and not yet using hava.io to visualise your running resources or perform cross platform and cross account searches using a single command, you really should check it out.
You can fully automate the generation and updating of your cloud infrastructure diagrams and security views across one or one thousand cloud accounts, hands free.

There is a free 14 day trial you can take, learn more about Hava using the button below:
AWS managed services will provision and manage technology stacks for your applications and workloads leaving you free to work on more important...
There are many free services provided by AWS including short trials, 12 month trials and always free services. In this post we take a look at what...
The AWS Cloud Practitioner Essentials Monitoring and Analytics module covers the AWS services available to ensure your AWS deployments are secure,...