aws
What is Amazon AWS Global Accelerator
AWS Global Accelerator provides fast highly available access to your cloud based applications using AWS edge infrastructure instead of the internet....

Amazon Aurora is an AWS RDS database service that brings together enterprise performance and scalability at pricing that’s more associated with harder to scale open source solutions.
Amazon Aurora is compatible with PostgreSQL and MySQL which provides low friction pathways when selecting a database for new projects or porting the databases from existing products.
AWS claim that Aurora is up to 5 times faster than MySQL and 3 times faster than PostgreSQL from the outset and will automatically scale to meet the demands of your applications. The database instances scale in increments of 10GB up to a maximum of 64TB. As a DB Admin or SysOps this is completely removes the need to worry about monitoring database size or RDS disk utilisation percentages as Aurora will automatically grow the database when required.
Aurora makes 6 copies of your data distributed across multiple locations and continuously backs up your databases to S3 storage as an additional safeguard.
For globally distributed solutions, Aurora can store data in multiple regions enabling fast local data access coupled with the ability to perform disaster recovery should any of the regions hosting your databases experience an outage.
It is reasonably easy to establish and scale an Aurora database, however if you have unpredictable workloads that are subject to traffic spikes, you can use Aurora Serverless to automatically start, scale and then shutdown database services once the demand has ceased.
Aurora can support up to 15 read replicas (10 more than native MySQL) and has a sub 10ms replica lag. This leads to a high availability database solution that has instantaneous failover should a segment or region fail. The strategy of storing 6 copies of your data across 3 availability zones provides hard to match resilience and the database continues to function even if 2 of the copies are unavailable when making database writes. Database reads are even more fault tolerant requiring only 3 out of the 6 copies to be functioning to make a successful read.
Behind the scenes the Aurora database will self-heal with peer-to-peer replication and will stripe data storage across hundreds of storage volumes automatically and supports cross region replication.
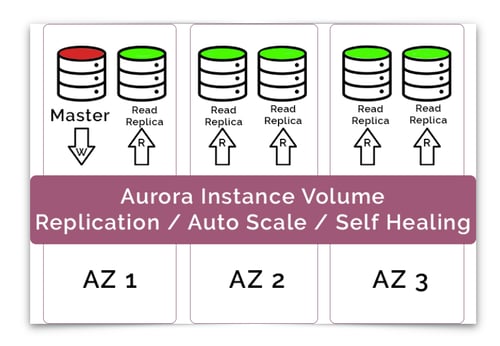
Keeping track of auto scaling resources can be tricky especially when self-healing processes can change the location of your master volume as a result of a failover. Likewise with up to 15 read replicas that can autoscale based on demand, the read volumes will appear and disappear periodically. Aurora handles this challenge by providing two endpoints.
The Writer Endpoint is a DNS name that remains constant and routes write requests to the current master volume. Should the master volume fail, one of the read replicas is promoted to the master volume and the writer endpoint will send writes to the new volume location. This means your client applications will not require any updates when the Aurora volume changes.
The same is true for reads. Aurora provides a Reader Endpoint that acts as a load balancer to access your read replicas. You don’t need to know how many read replicas have been provisioned by the autoscaler as the reader endpoint will handle read requests by routing to the best read replica volume.

Aurora is a fully managed service and will automatically handle all the backup and maintenance tasks you would normally need to consider. Things like automatic fail-over when a volume goes bad, backup and recovery, autoscaling, automated patching with zero downtime and routine maintenance tasks.
Aurora Backtrack is a tool incorporated into your Aurora DB cluster that allows you to restore specific data at any point in time without having to restore an entire backup.
Aurora provides the security features you would expect from AWS. It utilises encryption at rest using KMS, encrypts the automated backups and replicas and utilises SSL to protect data in transit. As with most AWS services, you will need to protect the Aurora Instance yourself using security groups.
If you are unsure of the amount of traffic your applications will need to serve, or you have applications that will be subject to intermittent spikes of traffic, then you can deploy your Aurora database using Aurora Serverless.
Aurora Serverless starts, scales and shuts down automatically in response to CPU load and connections. There are some limitations using serverless over a normal cluster, however it is possible to migrate from Serverless to Aurora Cluster and vice-versa.
AGD allows you to distribute your Aurora database and replicas across multiple regions. This enables fast global fail-over to secondary regions, fast cross-region migrations and low replication lag across regions with little to no performance impacts on your database performance. AGD currently supports MySQL 5.6/5.7 and PostgreSQL 10.11/11.7.
AGD achieves this using physical hardware replication technologies with the primary region hosting the master volume and read replication coupled to an outbound replication fleet that captures database changes and sends them to inbound replication technology hosted in the other regions hosting your Aurora DB read replicas. The remote readers typically have sub one second lag under heavy load.
Should the region hosting your master/write volume become unavailable, Aurora should take less than a minute to recover and promote an alternative read replica to accept full read/write workloads. AGD also supports high throughput of up to 200,000 writes per second.
All of this happens behind the scenes with no manual intervention from the users.
AGD provides the ability to write to any regional replica using database write forwarding. So essentially you read/write using the replica endpoint, AGS then forwards the write request to the primary region (master volume) and the replicates the changes back to all the read replicas.
To utilise write forwarding, you will need to enable it on the secondary regional clusters which can be done when setting up them up, or after the fact on existing regional clusters.
On top of enabling the write forwarding feature, you will also need to set a session parameter called aurora_replica_read_consistency which has 3 possible values:
Eventual : Changes written to the secondary region will only appear when the write is committed in the primary region and replicated back to the secondary region.
Session : Changes made in the secondary region are visible immediately to users connected to the secondary region prior to the write being committed to the primary region and replicated back.
Global : Changes are only visible when the master primary volume and all other secondary replicated regions have been synchronized. This approach ensures consistent data is visible across the entire regional network of aurora clusters.
Using write forwarding has some limitations. You cannot perform DDL commands like create table, alter table, create index etc when connected to a secondary region that has write forwarding enabled. Similarly you won’t be able to lock or flush tables, use savepoint/rollback, use XA transactions or load data infile type commands.
To create an Amazon Aurora database, access RDS under Databases in your AWS console.
Create a new database and select Aurora
Under the Aurora Options you can then select:
Then under settings you can name the cluster and set up log in credentials
And select an Aurora Instance class
The next option is Availability and Durability which allows you to switch off replication which will prevent replication and reader nodes being created in multiple availability zones. Switching off replication will of course reduce the resilience of the database.
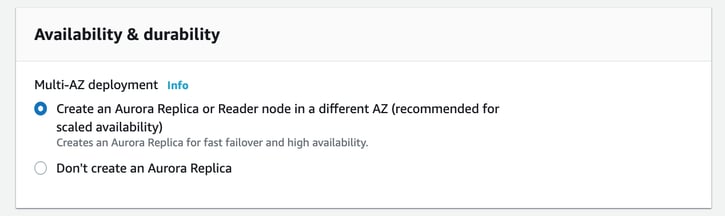
Next set up the connectivity options. Here you can specify an existing VPC to create the Aurora Cluster in. Once you create the database you cannot change the VPC.
In this option panel you can also grant public access to the database which will allow connect to the database via EC2 instances and other devices and a public IP address is generated. By default public access is set to No which means only resources within the VPC can access the database.
You may also choose an existing security group or create a new one.
The additional configuration options has a lot more configuration options:
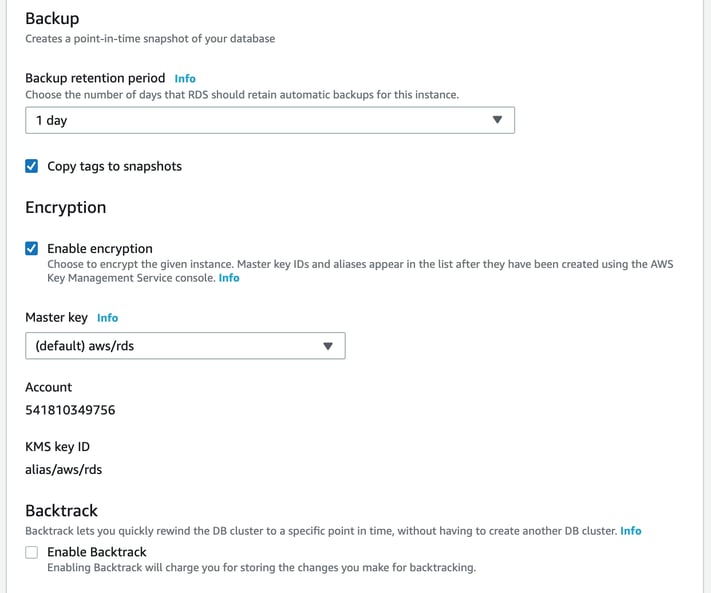
Backtrack will allow you to roll back your database to any specific point in time. If you want to roll back to 4pm last Tuesday, rollback will facilitate this without having to restore anything from backups. There is a storage charge for the information stored for use in performing a backtrack.
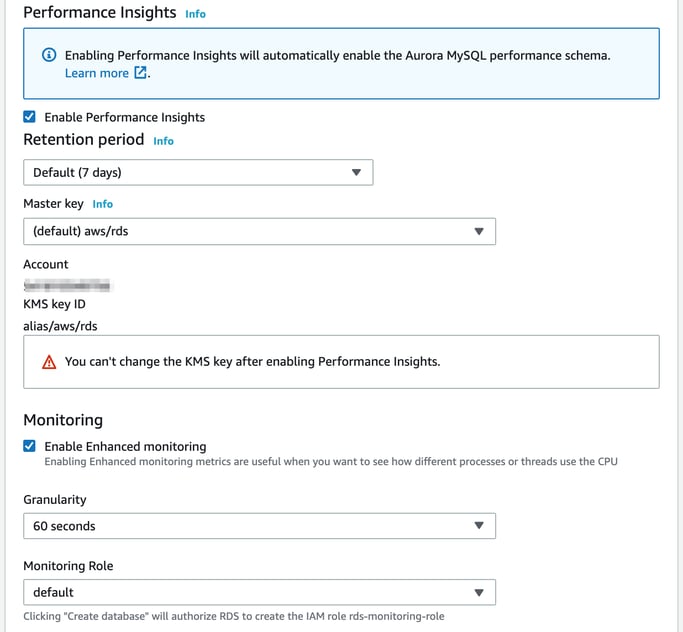
And the final section enables minor version upgrades to be performed automatically, selection of a preferred maintenance window and whether the database can be deleted remotely.
Once all the config options are set up as required, you can create the database which will take a few minutes.

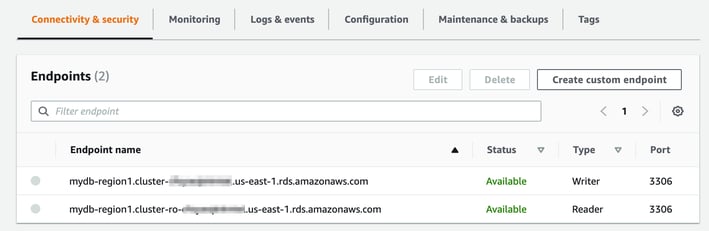
You can now open up the cluster to get the reader and writer endpoints
Once your first (primary) database is established, you can add another region to receive read replicas.
To do this open up the primary cluster and take the ‘Add AWS Region’ option from the actions menu
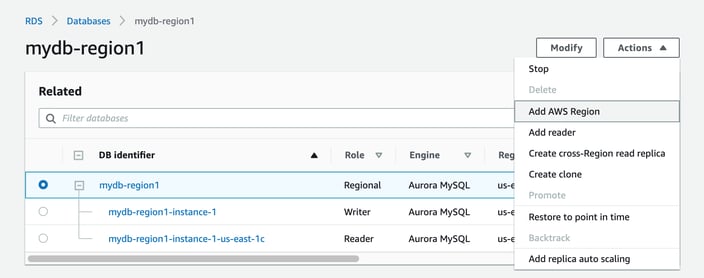
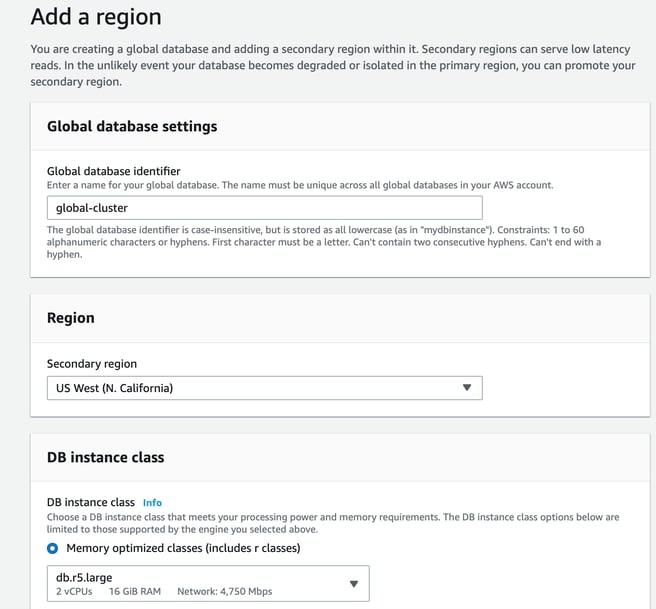
Here you name the global database, select the additional region and select an instance class.
You can also set up replication, connectivity and enable read replica write forwarding.
In the additional configuration you can name the new DB instances. In the below example we have used Global-Region2 to identify the cluster as the second region in the global database configuration.
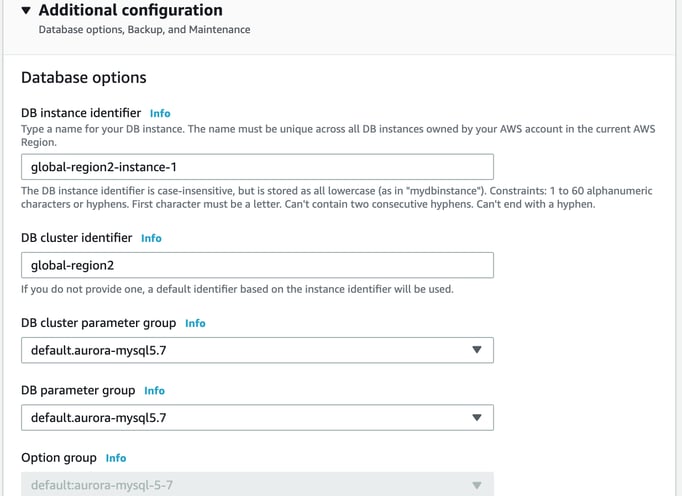
Once you are happy with the settings, you can add the region.
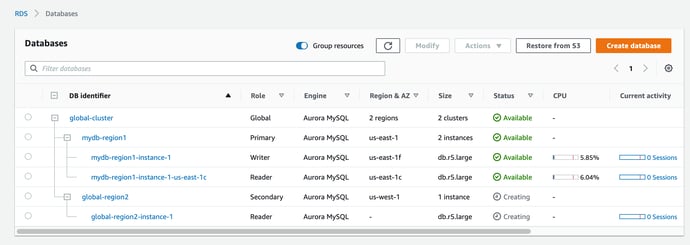
So that’s a quick overview of Amazon Aurora. As with all the Amazon RDS instances, you can visualize your AWS databases on diagrams automatically if you connect your AWS account to Hava.

To take a closer look at Hava you can open a free trial account and import some demo data. Learn more about Hava using the button below.
Read next: What is AWS Fargate
AWS Global Accelerator provides fast highly available access to your cloud based applications using AWS edge infrastructure instead of the internet....
In this post we take a look at the Security section of AWS Cloud Practitioner Essentials which covers what security measures AWS has built in and...
You can use SSO Single Sign On services to streamline the login and security for the applications, web properties and data you access frequently. In...