aws
How to Reduce Amazon AWS S3 Storage Costs
Monitoring usage and applying Lifecycle Policies to your Amazon S3 buckets and objects so that they end up in the most cost effective storage tier is...

Amazon Simple Storage Service (S3) allows you to safely store, retrieve and secure your files on the AWS ecosystem. Storage is segmented into repositories much like a traditional folder that are referred to as buckets.
In this article, we’ll take a look at the fundamentals of Amazon S3, it’s security features, how to permit or block public access to the data and how to use S3 at scale.

At the heart of the service, S3 is a data platform that stores objects in a flat structure that is segmented into single repositories known as buckets. All the objects are stored in a bucket at the same level. There is no physical folder/subfolder hierarchy, however using key name prefixes and delimiters, it is possible to organise the contents of a bucket in such a way that it imitates a folder/subfolder structure.
Unlike data lakes, databases or archival storage solutions, S3 has been designed to be as simple as possible, with minimal features, allowing it to be easy to use, highly available and scalable. S3 resides on the same global storage infrastructure that AWS uses to host it’s network of popular websites like amazon.com and primevideo.com
As well as data and media files S3 can be used for more complex uses like hosting a static html website.
By the way, S3 buckets are visualized on the AWS diagrams automatically generated by Hava.

Amazon refers to any piece of data you store in S3 as an object. Objects are stored at the same level in a bucket, however prefixes can be used to categorise objects which for all intents and purposes appear in the console interface as folders and subfolders, even though technically they aren’t.
AWS even refers to these non-folders as folders so it can get a little confusing when they insist that there are no folders, only prefixes.
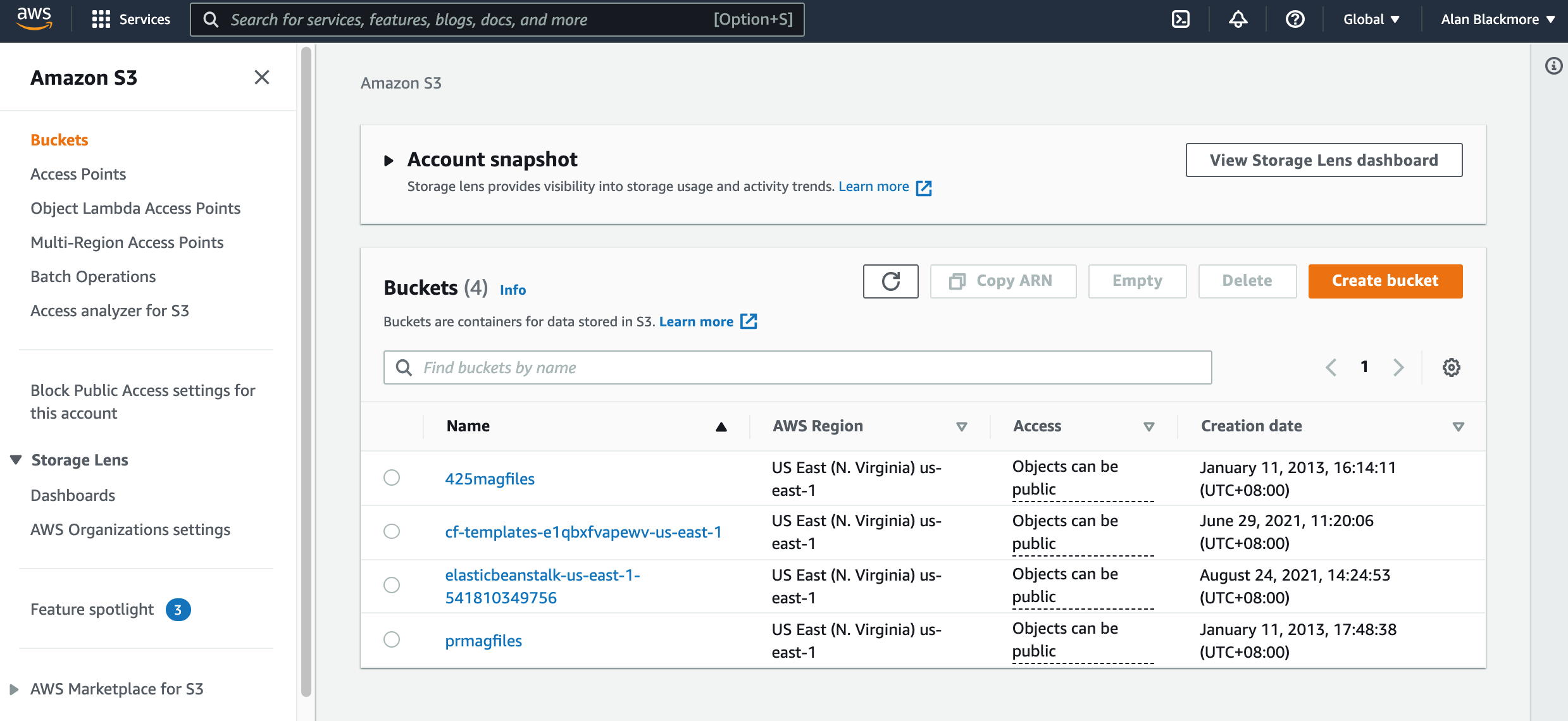
When you access the S3 service from your AWS Management Console, the first dashboard you reach shows you the buckets you have already set up and/or gives you the opportunity to add a new bucket.
In the example above I’ll select the last bucket “prmagfiles” from an old iBooks magazine project.
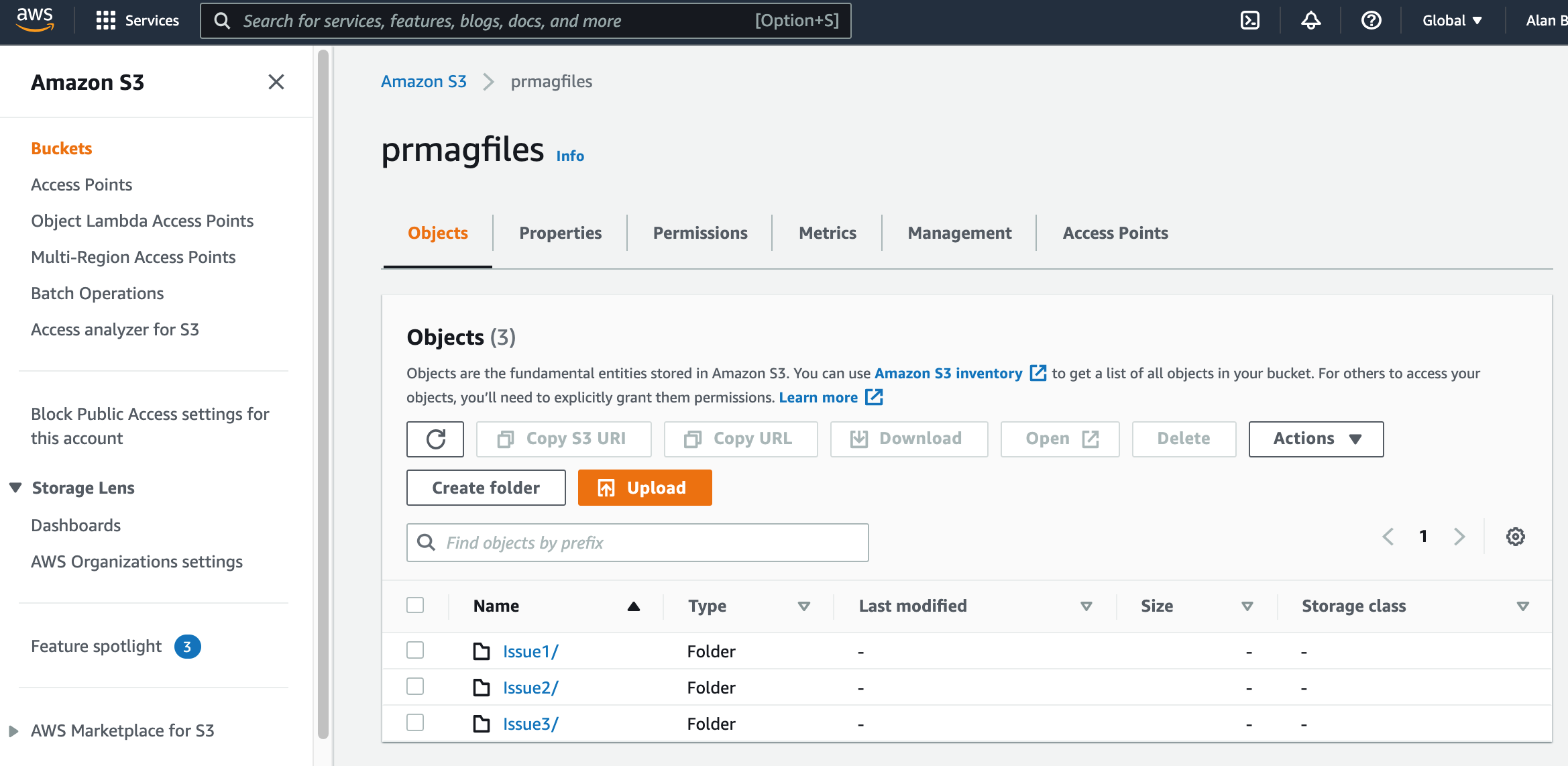
This particular bucket doesn’t have any files that are at the ‘root’ level as they are all placed in “folders” or in reality they have all been allocated a prefix. In this example we can look at the Issue1/ “folder”. All S3 bucket prefixes end with a trailing slash /.
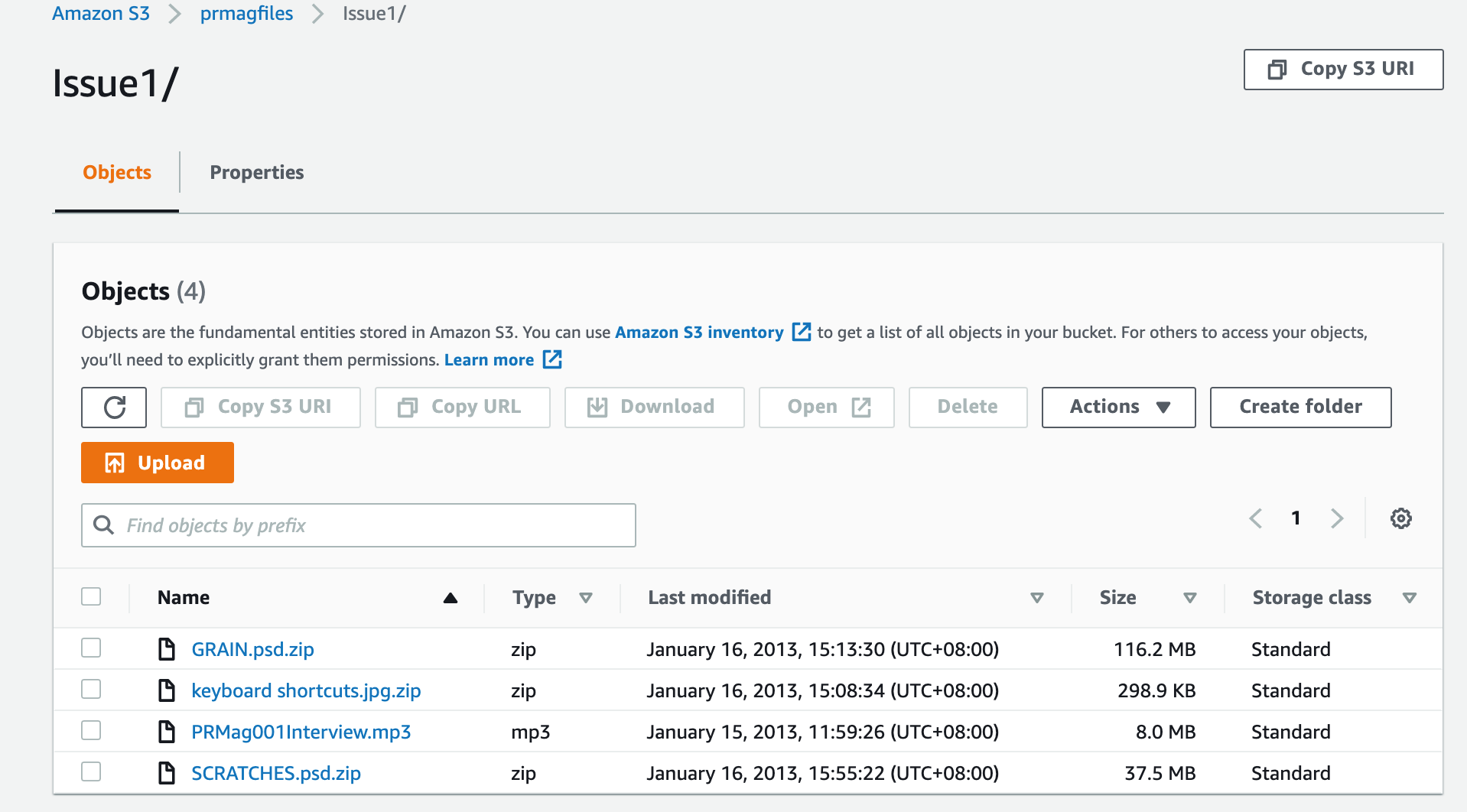
This particular group of objects prefixed with “Issue1/” is revealed when you select the Issue1 folder. Then we can select an object in the folder (that’s not really a folder) to see details about the object:
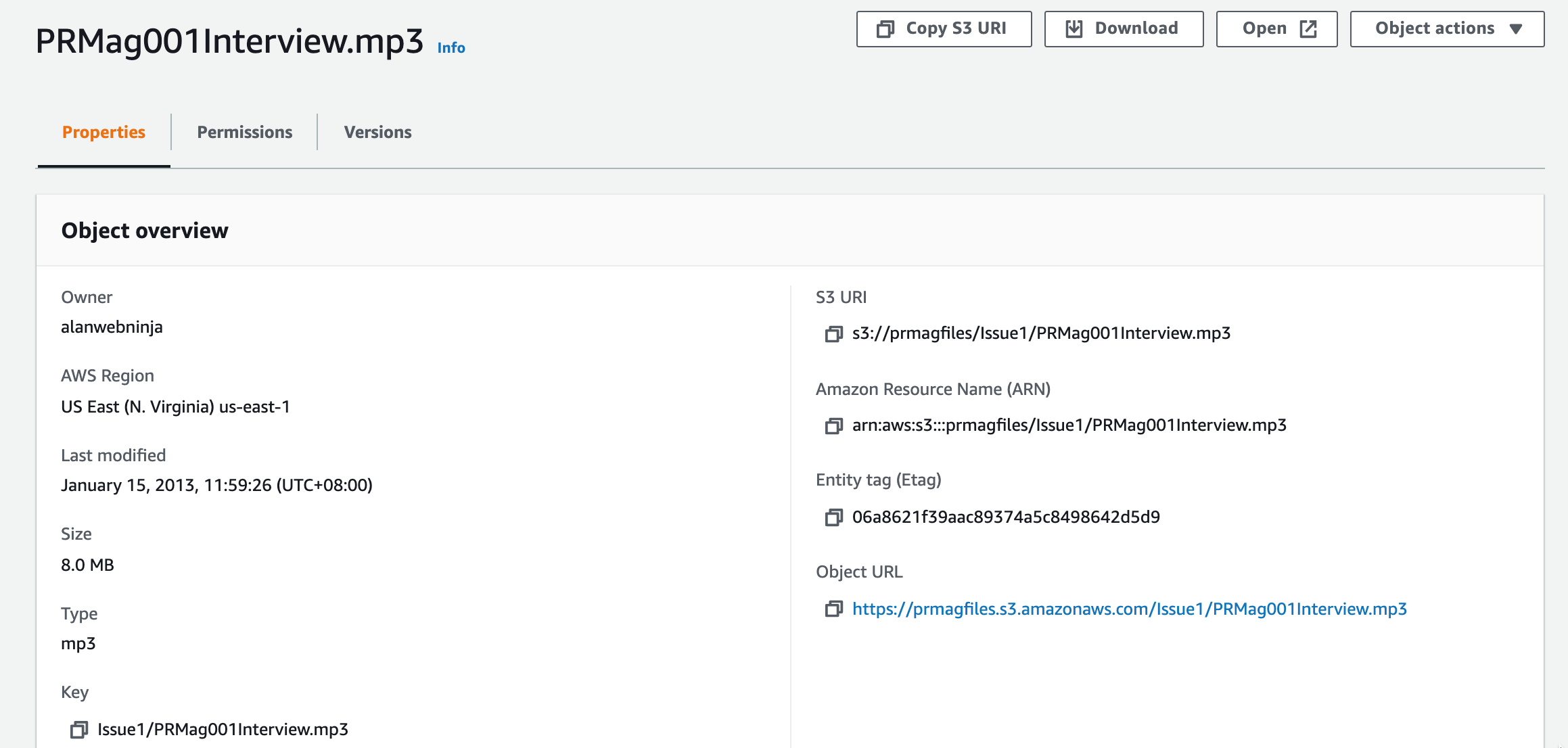
The above Object overview tells us the region, size, file type and date last modified as well as the S3 location of the file.
In this example : s3://prmagfiles/Issue1/PRMag001Interview.mp3
The bucket name is prmagfiles, the prefix is “Issue1/” and is followed by the object file name.
Buckets are permanent containers that scale to a virtually unlimited size when content is added to them. You don’t need to set or reserve a size like traditional file storage.
You can create up to 100 buckets in a standard AWS account. If you require more to keep projects or data in separate buckets you can submit a service level request which can scale the number of allowable buckets to 1000
The simplicity of S3 does bring with it a few limitations.
Buckets always belong to the account that created them. There is no way to transfer a bucket to another AWS account.
Bucket names are unique, not just in your account, but globally across the entire AWS S3 ecosystem. So you might need a few attempts to name your bucket if you are using a short name.
All bucket names are final. There is no way to change a bucket name once you create it, so if you are making the bucket public, choose wisely. You could of course create a new bucket and move the contents to it, but any links into files in the container would break.
You can only delete a bucket if it is empty. Once deleted the bucket name becomes available for re-use by any other AWS account after a 24 hour delay.
There is no limit to the number of objects that can be stored in a bucket, so you can keep all your objects in one bucket, or distribute them across several buckets. You are not allowed to nest buckets, i.e. you can’t create a bucket inside another bucket.
There is a limit of 100 buckets per standard AWS account, however you can apply for a service level increase to a maximum of 1000 buckets per account.
S3 bucket names form part of an addressable URL, so they need to be DNS compliant, which means there are a few rules to follow.
Obviously if you can follow an internal naming convention it will help you identify what the bucket is used for or what project it belongs to.
Ie https://my-ferret-site-images.s3.amazonaws.com is a lot easier to understand than https://2973726938743.s3.amazonaws.com
The bucket name rules are:
S3 object key names are made up of the optional prefix and object name. So a file sitting at the root level of the s3 bucket of say “myimage.png” the key is just “myimage.png”
If the file is sitting in a folder like “/images” the key would be “/images/myimage.png”
Objects stored in an S3 bucket can be a maximum of 5TB.
You can upload files up to 160GB via the AWS S3 console. Anything larger than that needs to be added via the AWS CLI or programmatically
If you enable versioning for a S3 bucket, AWS will generate a unique version id for an object. So should multiple versions of a file are written to the same bucket, all the versions will be stored and can be access with the unique version ID
This means when you enable versioning, each stored object has a version ID generated and multiple objects with the same key can exist in the bucket.
There are two categories of metadata that exist on objects. The system generated metadata like object type or object creation data which can only be updated by AWS.
Other types of metadata, like storage class, encryption levels etc are values you control.
You can control who can access objects in a S3 bucket using a number of mechanisms to control public access or controlled access for other AWS account users.
Under the permissions tab on a bucket you can block or allow public access, set up a bucket policy using JSON, define ownership rules for objects written into the bucket from other AWS accounts, set up an access control list and define a CORS cross origin resource sharing policy in JSON to define how resources in one domain can interact with resources in a different domain.
Like most AWS resources, tags can be applied to both buckets and objects to help track assets by any number definitions. A tag is a keypair consisting of a key and an optional value which you can use to categorise how the bucket or object fits into your organisation.
Tag pairs could for instance be used to separate development vs production assets, or separate projects, business units, client data or to apply cost allocation information.
So you could have a key pair of “ProjectStatus : Production” or “ProjectStatus : Development”
The tags can then be used to search for objects that have the required tag pair.
When you create a bucket and tag it, the tag is at the bucket level only. Existing objects and subsequently added objects do not inherit the bucket tag. You can add up to 10 tags on objects in a S3 bucket.
When you create a bucket, you need to specify which region you would like to create it in. This allows you to store data closer to your users or in specific geographic regions for regulatory compliance purposes.
This is fairly obvious, but you want to locate your data closest to where it will be accessed. In the situation where you have users distributed across the globe, you can set up cross-region replication, where your buckets and objects are replicated in other regions.
You can define whether you want to replicate an entire bucket, or just objects in the bucket with specific tags.
S3 allows you to host static websites by setting the bucket up for static website hosting via the bucket properties.
You simply tell the bucket the name of the index document (like index.html) and the supplied URL endpoint will give access to the website.
Once you create a bucket, there are a number of ways to add, read and delete objects.
The first is the AWS S3 console. When you open a bucket, you will be able to view, open and add files to the bucket.
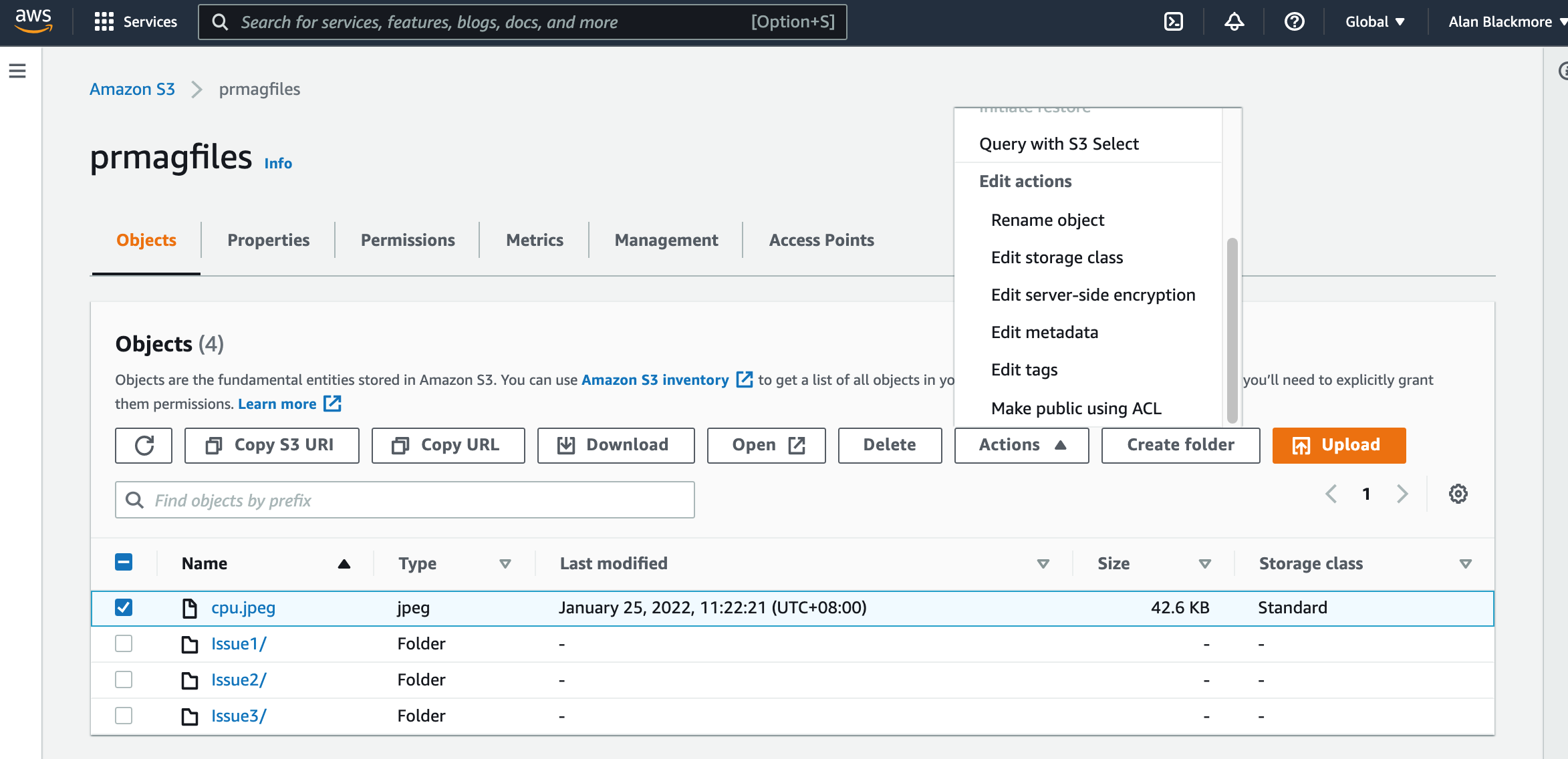
Here you can upload a file, select a file and perform a number of actions like obtain the URL to access the file directly, download the file, change the storage class (more on that later)
You can use the AWS CLI to interact with S3 via the AWS command line application and you can programmatically control S3 with the AWS SDK
An example of creating a bucket with the CLI you could use:
Aws s3 mb s3://my-new-bucket
Or
make_bucket: my-new-bucket
Copying a file to your S3 bucket is equally as simple:
aws s3 cp c:\documents\myimage.jpg s3://my-new-bucket
You can list your buckets and the content of a bucket from the CLI
aws s3 ls (lists all your buckets)
aws s3 ls s3://my-new-bucket (will list all the objects in your bucket)
Another option to interact with your S3 Bucket objects is the REST API. This is an HTTP interface to Amazon S3 that uses standard http requests to create, fetch and delete bucket objects.
As with all AWS services, security is approached with the principle of least privilege in mind. Access is highly restricted in the first instance and then gradually relaxed using a number of access policies.
Block Public Access is a feature that is enabled by default when you create a bucket. While you can apply BPA to individual buckets, it can also be applied at the AWS account level to prevent unauthorized access to resources in your AWS account.
IAM AWS Identity and access management can be used to control access to all AWS resources including buckets and objects. Within your IAM access policy attached to a user, group or role, you can include Effect/Action/Resource definitions to allow actions like Put / Get / Delete
Bucket policies can be used to configure individual permissions for the contents of a bucket, or you can use tags to apply policies to a subset of objects.
The policy is a JSON document that grants access to other AWS accounts or IAM users
Pre-Signed URLS can be issued. This gives temporary access to a bucket object using a temporary URL. This would be used if the person needing access to your object does not have any AWS credentials.
Access Control Lists are used to grant access to individual objects to authorised users.
Unless you need public access to the contents of your S3 buckets, it is recommended that you enable Block Public Access on your S3 buckets. One scenario for not enabling BPA on a bucket, would be if the bucket was hosting a static website
Data in transit to or from S3 is protected by the supported SSL/TLS client side encryption. This mitigates the possibility of a bad actor intercepting data travelling to or from S3. The AWS API is a REST service that supports SSL/TLS and the AWS SDKs and CLI tools use SSL/TLS by default.
For data at rest, Amazon S3 provides both server-side and client-side encryption.
Server-side encryption will encrypt your objects before saving them to disk and then decrypts when they are downloaded.
Client-side encryption can be employed using a customer master key (CMK) stored in AWS key management service (AWS KMS) which you use when uploading or downloading objects.
You can also use a master key stored in your application which you use to call the AWS S3 encryption client.
S3 has a number of storage classes available at different pricing based on the frequency and latency required. You can store data in deep deep archival storage that is super cheap but takes a while to retrieve.
The storage classes currently available are:
S3 Standard - high availability for frequently accessed data
S3 Intelligent-Tiering - automatically moves data to the most cost effective storage class based on access frequency
S3 Standard Infrequent Access (IA) - this os for less frequently accessed data, but you need immediate access when you need it
S3 One Zone IA - stores data in one zone instead of the normal 3 zones at a 20% saving
S3 Glacier Instant Retrieval - is cold storage for archival purposes where you can call up archived data immediately providing a 68% saving over standard S3
S3 Glacier Flexible - for backups and archived volumes that you may need to access once or twice a year and can wait a few minutes for the data to come back.
S3 Glacier Deep Archive - S3’s lowest cost storage class. Data can take up to 12 hours to retrieve.
So that's a look through the fundamentals of Amazon S3, one of the most popular AWS cloud services.
If you are building solutions on AWS and would like to visualise your S3 buckets on automatically generated network diagrams, then please consider taking advantage of a free 14 day trial of Hava.
Hava will visualise all your AWS resources creating a diagram for each discovered VPC and can be connected to your Azure and GCP accounts to generate independent platform network topology and security group visualisations as well as hybrid combinations of all three cloud platforms.
You can find out more about Hava here:
Monitoring usage and applying Lifecycle Policies to your Amazon S3 buckets and objects so that they end up in the most cost effective storage tier is...
AWS Backup is now integrated with Amazon S3. You can incrementally backup your S3 buckets using tags and resource ids.
Amazon Athena allows you to perform SQL queries on multiple data sources including S3 without having to ETL data. In this post we take a look at what...